Document Expansion: Overcoming Vocabulary Mismatch for Effective Information Retrieval
 June 20, 2023
June 20, 2023
Relevant papers
- Rodrigo Nogueira, Wei Yang, Jimmy Lin, and Kyunghyun Cho. 2019. Document Expansion by Query Prediction. arXiv:1904.08375 [cs.IR] (paper)
- Rodrigo Nogueira and Jimmy Lin. 2019. From doc2query to docTTTTTquery (paper)
- Mitko Gospodinov, Sean MacAvaney, and Craig Macdonald. 2023. Doc2Query--: When Less is More. arXiv:2301.03266 [cs.IR] (paper)
Introduction
The basic idea of document expansion is to augment the documents with related or representative terms to improve the retrieval performance in response to search queries. This technique is particularly useful in addressing the Vocabulary Mismatch problem.
The Vocabulary Mismatch Problem
The vocabulary mismatch problem is one of the central challenges in information retrieval. It occurs when the vocabulary used in the user's query does not match the vocabulary used in the documents that are relevant to that query.
The concept of similarity in information retrieval can be divided into two categories:
- Syntactic similarity: It refers to a linguistic relationship between two phrases in which they share a similar structure or formation. In the context of information retrieval, this similarity is generally based on the presence of identical keywords or phrases in the document and the search query.
- Semantic similarity: It refers to a similarity in meaning between two phrases. This similarity measure captures the relationship between words or phrases that may have different forms but share a similar meaning or talk about the same concept.
The following example illustrates the vocabulary mismatch problem and difference between syntactic and semantic similarity:
Document A:
... The current population of Nepal is 29,164,578 as per the 2021 census. The population growth rate is 0.92% per year. ...
Query:
How many people live in Nepal?
Here, the query and the document are semantically related, but they are syntactically different—the query does not contain the exact terms in the document except the term Nepal. This is a classic example of the vocabulary mismatch problem.
Now, let's say that we have another document:
Document B:
... Damien Rice will be performing at the Patan Museum Courtyard in Nepal on February. The live show is anticipated to attract many people. ...
We can see that this document contains most of the terms in the user query so it is syntactically similar to the query. However, they are not semantically similar and the document is not relevant to the query at all.
An ideal search engine should be able to tackle this issue by ranking Document A higher than Document B in terms of relevance. It should have the perfect balance between searching for syntactically as well as semantically similar documents.
Problems with classical ranking functions and inverted index structures
Inverted Index structures
An Inverted index is a traditional data structure used in information retrieval systems. It is a mapping from terms to the documents that contain those terms. It consists of a list of all the unique words that appear in any document, and for each word it consists of a list of the documents in which it appears, along with some metadata like its frequency or the position of the term in the document.
It allows for efficient keyword-based document retrieval, however, it inherently focuses on syntactic similarlity as it relies on term matching.
BM25 and other classical ranking functions
BM25 is a classical bag-of-words ranking model that relies on inverted indexes. It computes the relevance score of query terms to documents based on:
- Term Frequency: How often does the term occur in the document?
- Inverse Document Frequency: How often does the term occur in the collection of documents? We want to weigh special/rare terms higher.
For a query with terms and a document , the BM25 score is computed as follows:
where:
- is the frequency of term in document .
- is the length of document .
- is the average length of all documents in the collection.
- is the inverse document frequency of term .
The IDF score is computed as follows:
where:
- is the total number of documents in the collection.
- is the number of documents in the collection that contain the term .
Note: It is similar to TF-IDF, but it addresses some of its limitations:
- Term Frequency Saturation: BM25 uses a non-linear term frequency function that captures the notion of diminishing returns—the increase in relevance becomes smaller with each additional occurrence of a term in a document.
- Document Length Normalization: BM25 introduces a normalization factor that accounts for variations in document length, making it more robust when comparing documents of different lengths. Therefore, longer documents will not be favored due to having more occurrences of a term.
- Hyperparameters: BM25 introduces the hyperparameters and that allow for fine-tuning the weight of term frequency saturation and document length normalization.
Due to its simplicity and computational efficiency, BM25 is often employed as the first weak ranker in modern search engine's cascade of re-rankers. While these models remain strong baselines to rapidly filter and retrieve a candidate set of documents for further refinement by more sophisticated re-rankers, they suffer from the vocabulary mismatch problem.
If we were to use BM25 as the ranking function for our previous example, the irrelevant Document B would rank higher than the relevant Document A because it contains more frequency of query terms.
Tackling the Vocabulary Mismatch Problem
There are two main approaches to tackle the vocabulary mismatch problem in terms of expansion:
Query Expansion
Query expansion is a method to enrich the user's query with related terms or phrases in order to improve its accuracy in retrieving relevant document that might contain those terms.
There are many ways to perform query expansion:
- Relevance feedback: Utilizing user feedback, the search engine refines the query by incorporating relevant terms from top-ranking documents that users have deemed helpful.
- Thesaurus-based expansion: Using a thesaurus or a knowledge base, the search engine adds synonyms, antonyms, or related terms to the user's query.
- Co-occurrence analysis: The search engine identifies terms that frequently occur together with the query terms and adds them to the query, thereby capturing contextual relationships between the terms.
Query expansion is a topic for another blog, however, there are some drawbacks to this approach:
- Efficiency: It is computationally expensive as the cost of running an expanded query with many terms is very high.
- Topic Drifting: Since queries are normally short and carry little context, expanding the query might result in changing the topic of the query in an irrelevant direction.
Document Expansion
Document expansion, on the other hand, enhances the document representation by appending related terms, phrases, or potential queries to the original document. It aims to improve search effectiveness by matching the document to a broader range of relevant queries.
It addresses the drawbacks of query expansion:
- Efficiency: It is more efficient as document expansion is performed offline and does not require any additional computation at query time. Furthermore, it can be parallelized.
- Topic Drifting: Since documents are normally longer than queries, they carry more context and are less likely to drift away from the original topic.
Document Expansion by Query Prediction
The idea of performing document expansion by predicting relevant queries using deep neural networks was proposed by Nogueira et al. [1] in 2019.
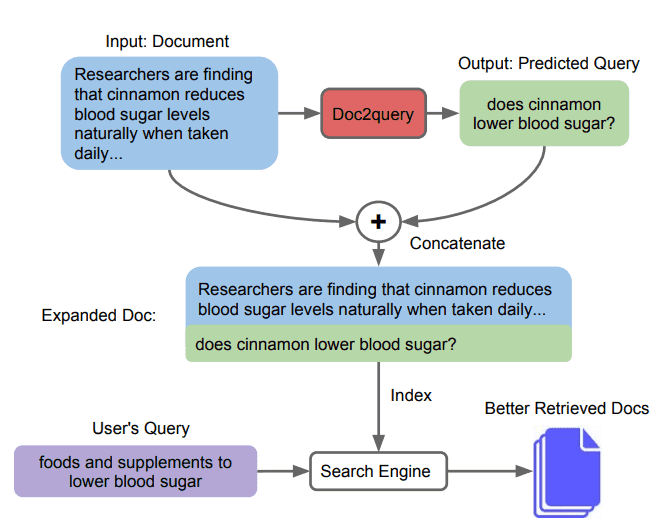
Given a document, the Doc2query model predicts a query, which is appended to the document. Expansion is applied to all documents in the corpus that are then indexed and searched as before.
The authors train a sequence-to-sequence transformer model (Vaswani et al., 2017) on a large corpus of documents and queries on the MS MARCO Datset and the TREC CAR Dataset.
Results
The authors show that using Doc2Query for document expansion as an intermediate step, outperforms the methods where Doc2Query is not used:
| TREC CAR (MAP) | MS MARCO (MRR@10) | Retrieval Time | ||
|---|---|---|---|---|
| Method | Test | Test | Dev | ms/query |
| BM25 | 15.3 | 18.6 | 18.4 | 50 |
| BM25 + Doc2Query | 18.3 | 21.8 | 21.5 | 90 |
| BM25 + RM3 | 12.7 | - | 16.7 | 250 |
| BM25 + Doc2Query + RM3 | 15.5 | - | 20.0 | 350 |
| BM25 + BERT (Nogueira & Cho, 2019) | 34.8 | 35.9 | 36.5 | 3400 |
| BM25 + Doc2Query + BERT | 36.5 | 36.8 | 37.5 | 3500 |
Note: RM3 is a query expansion technique (Abdul-Jaleel et al., 2004). The authors apply query expansion to both unexpanded documents (BM25 + RM3) as well as the expanded documents (BM25 + Doc2query + RM3) to compare the results.
From the above results, the authors present the contribution of Doc2Query as being orthogonal to that from post-indexing re-ranking.
Explanation
The improvement in scores using Doc2Query comes from two main factors:
- Term Reweighting: The model tends to copy some words from the input document, effectively performing term re-weighting (increasing the importance of key terms).
- Term Injection: The model injects terms that are relevant to the document but are not present in the document. This helps in capturing the vocabulary mismatch problem.
The authors report that on average, only 31% of the generated query terms are new while the rest 69% are copied.